数据网格与发现使团队了解数据生产成为可能,因此他们不会重复做无头工作。它避免了数据团队必须花费大量时间重新发现元数据的两种常见场景。首先,当企业雇佣新的专家时,这些数据治理平台专家具备数据驱动决策的知识,但缺乏数据背景。其次,当一个业务单元移动到一个不同的单元一段时间后返回时,会发现元数据在这段时间内完全改变了。
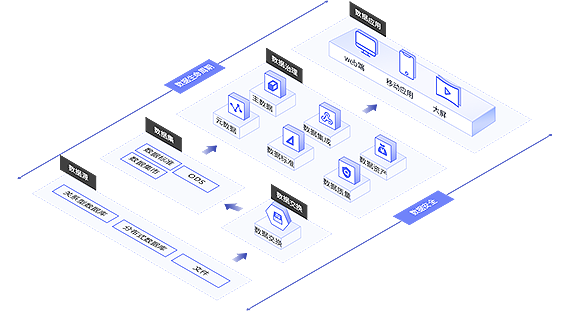
在任何给定的时间,组织都运行许多不同的数据模型来将数据记录到仓库中,并使其对用户可用。亿信华辰公司的数据仓库可能有200列和仪表板,它们与一个操作方面有关。这使得用户几乎不可能知道什么是唯一的真相来源。
数据网格中的发现有助于建立数据生产者和消费者之间的平衡,通过以下实践使数据更容易被发现和更可靠:
开源激发了共享所有权
就像在开源社区一样,数据可靠性和发现的所有权取决于与数据交互的每个人。数据发现失败的主要原因是数据没有足够的文档供用户获取值。这种来自开源方法的共同责任感激励用户解决他们发现的数据问题,从而为其他人省去麻烦。
自动化洞察力的集成
数据文档对于更好的发现至关重要,特别是对于产品的生产者来说,但与此同时,它只会创建更多的数据表。我们需要的是自动化来提取现有的、可操作的元数据,以增强发现透视图。用户可以使用自动化的洞察力来培养更好的文档,并创建传承来传播不同的信息。
简化用户体验
理解如何以及在何处使用数据来简化用户体验是很重要的。比如,这些数据主要用于销售报告,还是用于产品分析?一旦数据分析团队或业务智能团队可以定义如何查看数据分类的结构,其他人就可以贡献和维护该协议。简化的用户体验可以帮助文档化过程,或者促进最初的文档化工作,这些工作通常在数据发现时也需要进行。
将数据视为代码
在数据网格社区中,将数据和元数据视为代码是很常见的。当我们创建数据产品时,应该有使其有效的规则/文档,这些规则应该作为构建的系统的一部分应用。它需要有文档,包括合规标签、自动身份检查等。这些集成到数据发现平台中的系统大大降低了产生坏数据的可能性。
以代码为中心的发现
为了实现有效的数据治理(这通常会导致数据遵从性),数据发现应该以用户和代码为中心。它必须具有编程抽象,其中用户的数据发现抽象也适用于代码的数据发现,例如,特性或模型注册表。它们都需要后端,能够在运行时可靠地处理相关查询,这样用户就可以在运行时应用正确的策略,而不是将数据还原。
在任何给定的时间,组织都运行许多不同的数据模型来将数据记录到仓库中,并使其对用户可用。亿信华辰公司的数据仓库可能有200列和仪表板,它们与一个操作方面有关。这使得用户几乎不可能知道什么是唯一的真相来源。
数据网格中的发现有助于建立数据生产者和消费者之间的平衡,通过以下实践使数据更容易被发现和更可靠:
开源激发了共享所有权
就像在开源社区一样,数据可靠性和发现的所有权取决于与数据交互的每个人。数据发现失败的主要原因是数据没有足够的文档供用户获取值。这种来自开源方法的共同责任感激励用户解决他们发现的数据问题,从而为其他人省去麻烦。
自动化洞察力的集成
数据文档对于更好的发现至关重要,特别是对于产品的生产者来说,但与此同时,它只会创建更多的数据表。我们需要的是自动化来提取现有的、可操作的元数据,以增强发现透视图。用户可以使用自动化的洞察力来培养更好的文档,并创建传承来传播不同的信息。
简化用户体验
理解如何以及在何处使用数据来简化用户体验是很重要的。比如,这些数据主要用于销售报告,还是用于产品分析?一旦数据分析团队或业务智能团队可以定义如何查看数据分类的结构,其他人就可以贡献和维护该协议。简化的用户体验可以帮助文档化过程,或者促进最初的文档化工作,这些工作通常在数据发现时也需要进行。
将数据视为代码
在数据网格社区中,将数据和元数据视为代码是很常见的。当我们创建数据产品时,应该有使其有效的规则/文档,这些规则应该作为构建的系统的一部分应用。它需要有文档,包括合规标签、自动身份检查等。这些集成到数据发现平台中的系统大大降低了产生坏数据的可能性。
以代码为中心的发现
为了实现有效的数据治理(这通常会导致数据遵从性),数据发现应该以用户和代码为中心。它必须具有编程抽象,其中用户的数据发现抽象也适用于代码的数据发现,例如,特性或模型注册表。它们都需要后端,能够在运行时可靠地处理相关查询,这样用户就可以在运行时应用正确的策略,而不是将数据还原。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请发送邮件至 ZLME@xxxxxxxx@hotmail.com 举报,一经查实,立刻删除。